Frequency list
In computational linguistics, a frequency list is a sorted list of words (word types) together with their frequency, where frequency here usually means the number of occurrences in a given corpus. A short example could be:
| the | 3789654 |
| he | 2098762 |
| [...] | |
| king | 57897 |
| boy | 56975 |
| [...] | |
| outragious [sic] | 76 |
| [...] | |
| stringyfy | 5 |
| [...] | |
| transducionalify | 1 |
It seems that Zipf's law holds for frequency lists drawn from longer texts of any natural language. Frequency lists are a necessary prerequisite for building of an electronic dictionary, which is by itself a prerequisite for a wide range of applications in computational linguistics.
German linguists define the häufigkeitsklasse (frequency class) 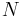 of an item in the list using the base 2 logarithm of the ratio between its frequency and the frequency of the most frequent item. The most common item belongs to frequency class 0 (zero) and any item that is approximately half as frequent belongs in class 1. In the example list above, the misspelled word outragious has a ratio of 76/3789654 and belongs in class 16.
of an item in the list using the base 2 logarithm of the ratio between its frequency and the frequency of the most frequent item. The most common item belongs to frequency class 0 (zero) and any item that is approximately half as frequent belongs in class 1. In the example list above, the misspelled word outragious has a ratio of 76/3789654 and belongs in class 16.
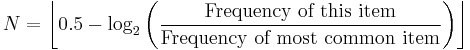
where 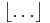 is the floor function.
is the floor function.
Frequency lists, together with semantic networks, are used to identify the least common, specialized terms to be replaced by their hypernyms in a process of semantic compression.
References
- Helmut Meier: Deutsche Sprachstatistik. Hildesheim: Olms 1967. (frequency list of German words)